
Andrej Karpathy称赞!斯坦福队的新工作,让我们雅
发布时间:2025-06-06 10:33
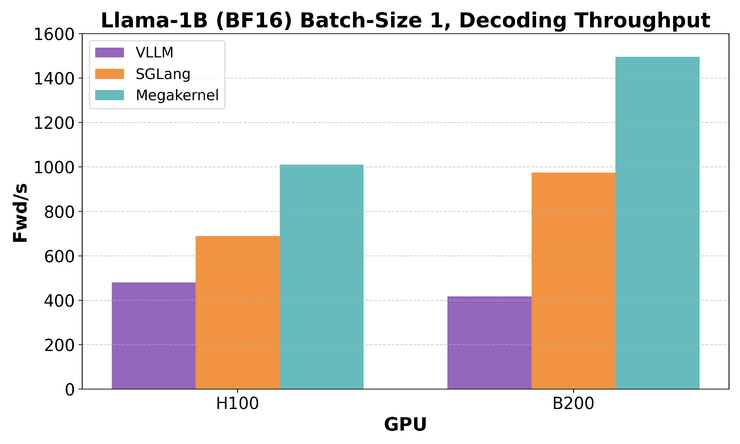 斯坦福大学朦胧的研究团队刚刚宣布了重大优化:他们将期权型号的开放资源从“ Megakernel”的开放资源中融合到了“ Megakernel”,并将低压能力推向了极限。在某些具有非常高实时功能的应用程序中,例如AI对话和涉及人的交互式工作流程,大语言模型的响应速度不仅很重要,而且还可以确定用户体验的成功或失败。该团队认为,限制LLM推理速度的瓶颈是内存加载的真正问题。研究之后,他们发现推理引擎的现有开源(例如VLLM,sglang)即使在其连续的过度低层压活动中,即使在顶级GPU(例如H100)中,也只能使用不到50%的记忆带宽。这主要是因为变压器模块的每一层都以-disassembled在十二架的方式中 - 有cuda内核,每个内核执行的操作非常小(例如RMS Norm,注意力,MLP,MLP,旋转位置嵌入等),许多环境之间移动并等待它们。更严重的是,启动和完成这些内核的成本并不能完全被诸如CUDA图或PDL(程序化依赖发射)之类的机制完全掩盖,但会在短期活动中加强。换句话说,GPU花费大量时间“等待工作”而不是“工作”。对Hazy团队的研究也围绕着这个问题展开。 Megakernel:让我们谈谈加入零设计的想法的实验结果。在H100中识别Megakernel的延迟是该压缩在不到1毫秒的情况下,并且记忆带宽的使用率高达78%,比VLLM高2.5倍,比Sglang高1.5倍。在更高级的B200平台上,延迟进一步降低至600〜680微秒,接近理论上限。评判从完整理解的时间分布中,使用250微秒来激活存储,等待一致性和数据加载,并将200微秒用于RMSNorm和MATVEC(其中MATVEC占95%)。负载重量仅需30微秒,流量机理稳定。经线和屏障之间的功能障碍带有40微秒的延迟,而其余的不同开销(例如设置,传递参数和页面状态)标记了整个Tungkol,以80微秒为单位。通常,通过仔细的安排,朦胧团队的Megakenenel几乎将当前的硬件性能挤压到极限。上述效果确实与Hazy团队提出的激进但有效的设计思想相关:将整个沟通过程与单个CUDA KSI ERNEL(也称为Megakernel)相结合。在实验中,他们开发了一个基于Thundermla现有的GPU操作的轻质“指令解释器”建筑学。该系统由每个流多处理器(SM)的“实施计划”预先分配,其中包含许多指令,每个指令都代表变压器模型中的结构单位单位。这些说明包括:复合说明Fuse rmsnorm,QKV投影和绳索;对矩阵繁殖的关注Andalmonds减少(支持长期GQA); o预测和剩余添加; RMSNORM,GATE(SILU)的激活和MLP的向上投影;下降和最终残留; RMSNORM +语言建模头的最后一层。每个指令都是基于单个CUDA模板构建的,实现了加载,商店和计算的标准化封装。在运行之前,翻译人员在静态组织中进行了实施依赖性,每个SM可以反复使用相同的时间表来处理许多令牌。此外,为了确保良好的数据路径,翻译人员将在静态协调实现离子计划根据模型结构,避免在调度期间避免动态分支,并提高吞吐量和并发实现功能。同时,为了实现流量计算并防止共享内存冲突,团队还达到了共享的GPU内存,例如:将第一个213KB共享内存分为13 16页;其余的用于存储指令参数,页面分配信息等;每个指令在加载前显示请求页面,完成后翻译器的翻译器将返回给它。页面发布后,转换器将立即将其分配给下一个指令。该机制可确保下一阶段的计算可以尽早开始预加载权重,从而最大程度地提高带宽的使用和“气泡”去除。但是,巨型的结构不能依赖于内核之间同步的传统隐式隐式,因此朦胧的团队也使用了计数器系统:Pinathey将在全局内存中维护一组整数,完成每个指令后,在相应的计数器上为+1。如果指令取决于上一步的结果,则它将等待在执行之前到达一定数量的计数器。示例:在MLP下的投影阶段,团队将中间状态分为4个块,每个块在写作后立即提示后续计算,从而实现了类似的流动。此外,团队还准确地设置了依赖图图,避免了全球障碍,大大减少了指令之间等待的浪费,并使整个内核都被困在理论上的连接附近。此外,研究小组还测量了CUDA异步屏障的性能,并发现尽管障碍物已“通过”,但距离也是每小时60ns,而重合操作的成本也不容忽视。在实际实施中,尤其是在大专业中他们发现,诸如矩阵矢量之类的操作发现,使用常规的CUDA核心(非张量核心)在Hopper体系结构(例如H100)中可能更有效,但张量核心具有Blackwell Architecture的优势。它还表明,在不同一代的硬件中,最佳的Megakernel实现路径也应适用于微结构差异,而不是所有平台共有的一组解决方案。为什么传统的推理方法无效?在详细解释Megakernel的构建之前,朦胧的团队实际上返回并遵守了一个关键问题:为什么今天的主流LLM推理系统在今天的表现如此“不好”,例如小批次和超级潜伏期。他们发现,诸如VLLM和SGLANG之类的系统在处理诸如开发令牌之类的限制情况时,使用GPU内存的使用确实很低。主要原因是远期模型过程在许多小的CUDA内核中受损。那IS,模型上的每个小操作(例如RMSNORM,MLP层)都是单独的内核。这种“微核模式”看起来模块化且易于维护,但确实隐藏了一个大型性能。每个内核的开始和破坏确实具有固定成本 - 您可以将其理解为“如果您更改一些任务,则应进行维修。”在极低的延迟情况下,这个“会议”时间成为开销的主要来源。此外,当GPU是这些小内核的staplekbo时,通常会粘在“尾巴”上 - 例如,内核需要512个线程块即可运行,但是GPU只有148个实现单元(SMS),因此随后的线程块只能为前面的慢速结束,从而导致慢速结束,从而导致许多IDRESS。即使使用诸如CUDA和PDL图(程序化依赖性启动)之类的加速器,仍然需要1.3至2.1微秒来启动内核。在此期间,GPU确实什么也没做,只是在等待环境移动。有什么恶化e是,因为这些内核与串行一致,所以下一个内核无法下载其要预先使用的数据,从而导致GPU访问全局内存和带宽无法使用。它构成了所谓的“内存管道气泡” - 计算和计算之间总是存在差距。 GPU显然不会出去,但仍然停止等待。示例:H100的带宽为3.35TB/s。原因是Llama-1b每小时只需要2.48GB。从理论上讲,它可以将1350向前运行至1秒。但是,由于模型的每一层都需要运行7个内核,总共需要16层。尽管每个内核仅带有5微秒的摊位,但总潜伏期的性能将其提高到770次,实际上可能较小。因此,朦胧的团队清楚地指出:这个问题不是内核速度缓慢的问题,而是系统的徒劳。单独优化内核确实是没有用的。核心是杀死这个内核的边界nd停止Pagpu当时让它移动。这是他们大型提议的主要动机。现代LLM通常具有十二或一百个五百变压器,每一层都包含RMSNORM,注意力,MLP和其他操作。为了使其清晰易于执行,主情节将它们分解成小内核,每个核心都做了一些小事情,就像装配线中的工人一样。但是问题在于管道正在经常移动,并且随着每个“更改”的延迟,它也会导致访问GPU视频内存,而GPU视频内存始终是连续的,带宽效率会恶化。更严重的是,即使某些CUDA机制似乎用于优化,但在这种极端情况下,它们实际上是“障碍”。例如,PDL的CudaGridDepentencencencentize将迫使所有thetask在继续前进之前完成,这意味着即使某些任务准备就绪,他们也必须一起等待。因此,在最终分析中,leifeng.com(公共帐户:leifeng.com)b在“单个序列,毫秒响应”等场景中,推理系统的当前体系结构无效,并且在系统级别无效。仅通过重建整个实施方法并允许GPU移动较少,并且可以同时进行更多的操作,就可以真正消耗其计算能力。这是Megakernel的价值。
斯坦福大学朦胧的研究团队刚刚宣布了重大优化:他们将期权型号的开放资源从“ Megakernel”的开放资源中融合到了“ Megakernel”,并将低压能力推向了极限。在某些具有非常高实时功能的应用程序中,例如AI对话和涉及人的交互式工作流程,大语言模型的响应速度不仅很重要,而且还可以确定用户体验的成功或失败。该团队认为,限制LLM推理速度的瓶颈是内存加载的真正问题。研究之后,他们发现推理引擎的现有开源(例如VLLM,sglang)即使在其连续的过度低层压活动中,即使在顶级GPU(例如H100)中,也只能使用不到50%的记忆带宽。这主要是因为变压器模块的每一层都以-disassembled在十二架的方式中 - 有cuda内核,每个内核执行的操作非常小(例如RMS Norm,注意力,MLP,MLP,旋转位置嵌入等),许多环境之间移动并等待它们。更严重的是,启动和完成这些内核的成本并不能完全被诸如CUDA图或PDL(程序化依赖发射)之类的机制完全掩盖,但会在短期活动中加强。换句话说,GPU花费大量时间“等待工作”而不是“工作”。对Hazy团队的研究也围绕着这个问题展开。 Megakernel:让我们谈谈加入零设计的想法的实验结果。在H100中识别Megakernel的延迟是该压缩在不到1毫秒的情况下,并且记忆带宽的使用率高达78%,比VLLM高2.5倍,比Sglang高1.5倍。在更高级的B200平台上,延迟进一步降低至600〜680微秒,接近理论上限。评判从完整理解的时间分布中,使用250微秒来激活存储,等待一致性和数据加载,并将200微秒用于RMSNorm和MATVEC(其中MATVEC占95%)。负载重量仅需30微秒,流量机理稳定。经线和屏障之间的功能障碍带有40微秒的延迟,而其余的不同开销(例如设置,传递参数和页面状态)标记了整个Tungkol,以80微秒为单位。通常,通过仔细的安排,朦胧团队的Megakenenel几乎将当前的硬件性能挤压到极限。上述效果确实与Hazy团队提出的激进但有效的设计思想相关:将整个沟通过程与单个CUDA KSI ERNEL(也称为Megakernel)相结合。在实验中,他们开发了一个基于Thundermla现有的GPU操作的轻质“指令解释器”建筑学。该系统由每个流多处理器(SM)的“实施计划”预先分配,其中包含许多指令,每个指令都代表变压器模型中的结构单位单位。这些说明包括:复合说明Fuse rmsnorm,QKV投影和绳索;对矩阵繁殖的关注Andalmonds减少(支持长期GQA); o预测和剩余添加; RMSNORM,GATE(SILU)的激活和MLP的向上投影;下降和最终残留; RMSNORM +语言建模头的最后一层。每个指令都是基于单个CUDA模板构建的,实现了加载,商店和计算的标准化封装。在运行之前,翻译人员在静态组织中进行了实施依赖性,每个SM可以反复使用相同的时间表来处理许多令牌。此外,为了确保良好的数据路径,翻译人员将在静态协调实现离子计划根据模型结构,避免在调度期间避免动态分支,并提高吞吐量和并发实现功能。同时,为了实现流量计算并防止共享内存冲突,团队还达到了共享的GPU内存,例如:将第一个213KB共享内存分为13 16页;其余的用于存储指令参数,页面分配信息等;每个指令在加载前显示请求页面,完成后翻译器的翻译器将返回给它。页面发布后,转换器将立即将其分配给下一个指令。该机制可确保下一阶段的计算可以尽早开始预加载权重,从而最大程度地提高带宽的使用和“气泡”去除。但是,巨型的结构不能依赖于内核之间同步的传统隐式隐式,因此朦胧的团队也使用了计数器系统:Pinathey将在全局内存中维护一组整数,完成每个指令后,在相应的计数器上为+1。如果指令取决于上一步的结果,则它将等待在执行之前到达一定数量的计数器。示例:在MLP下的投影阶段,团队将中间状态分为4个块,每个块在写作后立即提示后续计算,从而实现了类似的流动。此外,团队还准确地设置了依赖图图,避免了全球障碍,大大减少了指令之间等待的浪费,并使整个内核都被困在理论上的连接附近。此外,研究小组还测量了CUDA异步屏障的性能,并发现尽管障碍物已“通过”,但距离也是每小时60ns,而重合操作的成本也不容忽视。在实际实施中,尤其是在大专业中他们发现,诸如矩阵矢量之类的操作发现,使用常规的CUDA核心(非张量核心)在Hopper体系结构(例如H100)中可能更有效,但张量核心具有Blackwell Architecture的优势。它还表明,在不同一代的硬件中,最佳的Megakernel实现路径也应适用于微结构差异,而不是所有平台共有的一组解决方案。为什么传统的推理方法无效?在详细解释Megakernel的构建之前,朦胧的团队实际上返回并遵守了一个关键问题:为什么今天的主流LLM推理系统在今天的表现如此“不好”,例如小批次和超级潜伏期。他们发现,诸如VLLM和SGLANG之类的系统在处理诸如开发令牌之类的限制情况时,使用GPU内存的使用确实很低。主要原因是远期模型过程在许多小的CUDA内核中受损。那IS,模型上的每个小操作(例如RMSNORM,MLP层)都是单独的内核。这种“微核模式”看起来模块化且易于维护,但确实隐藏了一个大型性能。每个内核的开始和破坏确实具有固定成本 - 您可以将其理解为“如果您更改一些任务,则应进行维修。”在极低的延迟情况下,这个“会议”时间成为开销的主要来源。此外,当GPU是这些小内核的staplekbo时,通常会粘在“尾巴”上 - 例如,内核需要512个线程块即可运行,但是GPU只有148个实现单元(SMS),因此随后的线程块只能为前面的慢速结束,从而导致慢速结束,从而导致许多IDRESS。即使使用诸如CUDA和PDL图(程序化依赖性启动)之类的加速器,仍然需要1.3至2.1微秒来启动内核。在此期间,GPU确实什么也没做,只是在等待环境移动。有什么恶化e是,因为这些内核与串行一致,所以下一个内核无法下载其要预先使用的数据,从而导致GPU访问全局内存和带宽无法使用。它构成了所谓的“内存管道气泡” - 计算和计算之间总是存在差距。 GPU显然不会出去,但仍然停止等待。示例:H100的带宽为3.35TB/s。原因是Llama-1b每小时只需要2.48GB。从理论上讲,它可以将1350向前运行至1秒。但是,由于模型的每一层都需要运行7个内核,总共需要16层。尽管每个内核仅带有5微秒的摊位,但总潜伏期的性能将其提高到770次,实际上可能较小。因此,朦胧的团队清楚地指出:这个问题不是内核速度缓慢的问题,而是系统的徒劳。单独优化内核确实是没有用的。核心是杀死这个内核的边界nd停止Pagpu当时让它移动。这是他们大型提议的主要动机。现代LLM通常具有十二或一百个五百变压器,每一层都包含RMSNORM,注意力,MLP和其他操作。为了使其清晰易于执行,主情节将它们分解成小内核,每个核心都做了一些小事情,就像装配线中的工人一样。但是问题在于管道正在经常移动,并且随着每个“更改”的延迟,它也会导致访问GPU视频内存,而GPU视频内存始终是连续的,带宽效率会恶化。更严重的是,即使某些CUDA机制似乎用于优化,但在这种极端情况下,它们实际上是“障碍”。例如,PDL的CudaGridDepentencencencentize将迫使所有thetask在继续前进之前完成,这意味着即使某些任务准备就绪,他们也必须一起等待。因此,在最终分析中,leifeng.com(公共帐户:leifeng.com)b在“单个序列,毫秒响应”等场景中,推理系统的当前体系结构无效,并且在系统级别无效。仅通过重建整个实施方法并允许GPU移动较少,并且可以同时进行更多的操作,就可以真正消耗其计算能力。这是Megakernel的价值。  扫一扫,官方微信
|